I used to be very up to date on self-supervised learning, but fell out of it as the field itself slowly died down in favor of VLMs and what not after SigLIP/DINO/V-JEPA became the dominant paradigms. This means I haven’t read any SSL papers seriously since 2023.
However, that doesn’t mean I’ve been living under a rock. I’m still well aware of Yann LeCun’s anti-pixel prediction tirade, and in that time, nothing came out that convinced me we could move away from pixel-level supervision. It’s simply such a strong prior to enact for self-supervision: you get multi-view consistency and true spatial grounding at the slight cost of having to model high-frequency pixel details.
Yann dropped by Princeton this week to give a talk, and I was shocked by how much JEPA work had happened since my hiatus from SSL. All sorts of information-theoretical regularization methods and applications of JEPA had come out, which piqued my interest. I even got to ask him why he was against pixel prediction. His main point was that Kaiming had tried for years before giving up and going to MIT. But I needn’t feel bad—it took Yann 10 years to figure out pixels were not it, so it was okay if it took me 3 days. Funny guy honestly.
I also happened to just give a reading group on LeWorldModel [1] this afternoon. I’m in a very JEPA time of my life, if you can’t tell.

Title slide for my reading group presentation. I got a bit carried away and forgot which LeGOAT I was supposed to be talking about…
In the wake of that, I’ve gotten a chance to revisit the literature from the beginning and understand what JEPA argues for, marketing and Twitter drama aside. This post (and hopefully a series) is my documentation of interesting discoveries I make, some more obvious than others. Spoiler alert: I think JEPA has some legs to it!
JEPA is an objective, not a prior
Based on how Yann markets it, I always assumed JEPA was about forgoing pixel-level supervision and thus its priors. I also figured that it was its own type of self-supervised learning, similar to the other host of contrastive/distillation approaches with its minor tweaks. But they’re actually more similar than I had thought.
![High level comparison of JEPA to other SSL methods, from [9].](https://blog.tylerzhu.com/images/lethoughts/jepa_intuitive.png)
High level comparison of JEPA to other SSL methods, from [9].
This is a schematic for comparison of different self-supervised methods. Under the first category of joint-embedding architectures, you have methods which pull together similar concepts and push away dissimilar ones. This relies heavily on data augmentation to obtain “self-similar” views of the data to do this without labels. The canonical example is SimCLR [2], but pretty much everything falls under this category: MoCo [3], BYOL [4] (i.e. non-contrastive methods), DINO [5], and even multimodal examples like CLIP [6] or SigLIP [7] where $x,y$ are text and image encoders and $D(s_x, s_y)$ is a contrastive loss (i.e., a softmax or sigmoid over each modality per class). The central concern is representation collapse, i.e., preventing everything from becoming the same embedding.
The second category is generative architectures, or reconstruction-based methods. These predict directly in pixel space, which prevents collapse issues as long as $z$ has less information capacity than the signal $y$. Masked Autoencoders [8] are the canonical reference, where $z$ consists of the mask tokens that the decoder learns to predict from unmasked context $x$.
The final category is joint-embedding predictive architectures. The key difference to generative methods is that they predict in latent space, not pixel space. As a result, they also suffer from collapse issues, which can be addressed through similar techniques above like assymetric architectures.
A slight difference between joint-embedding architectures and others is that the first generally seeks “invariance” to data-augmentations, whereas the latter two seek representations that are “predictive” of each other when given some conditioning signal $z$.
I-JEPA is surprisingly DINO (to me)
Let’s take the Image-JEPA (I-JEPA) [9] architecture as an example below. We have a context encoder $f_\theta$ whose job is to encode a partial crop of the input into enough information for the predictor $g_\phi$, conditioned on positional tokens (colored), to predict a target representation. In true JEPA fashion, we supervised with an $L_2$ loss defined on the latent representations, where the target encoder is an exponential moving average (EMA) of the context for assymetry.
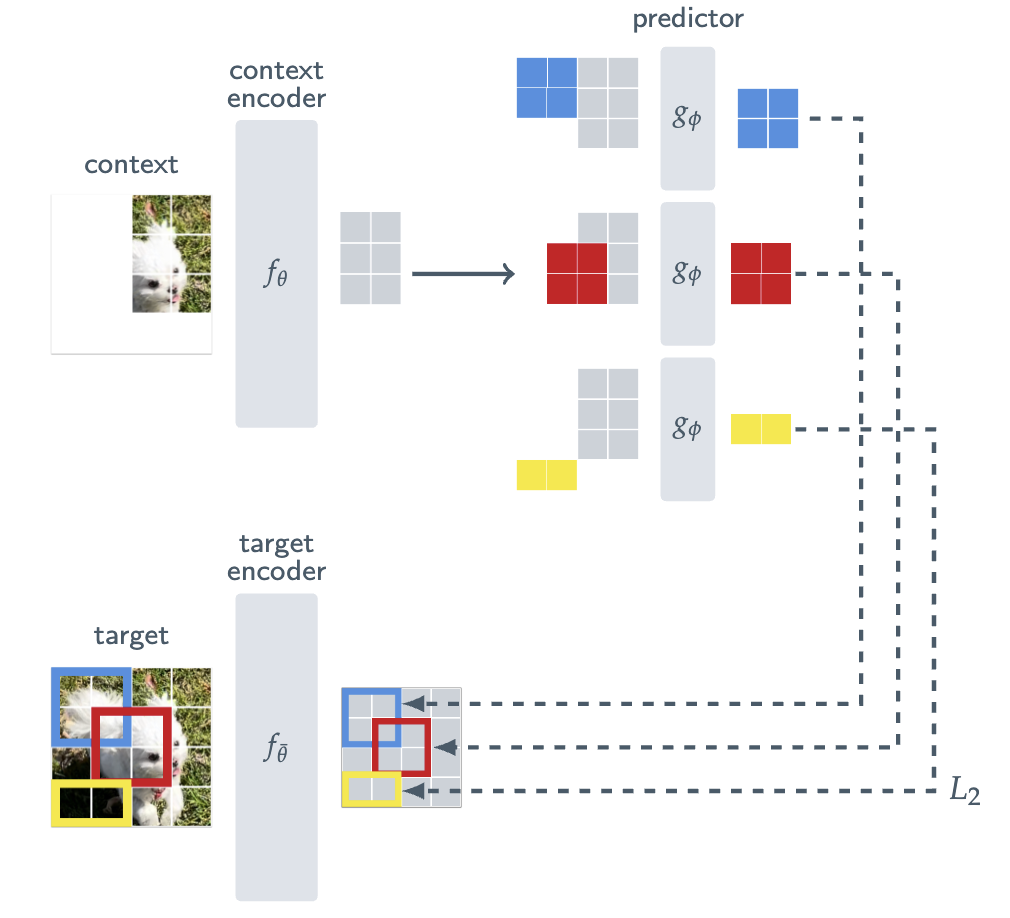
Overview of the I-JEPA architecture, where the goal is to predict target region representations based on a specific context.
Look familiar? If you squint, it’s just the DINO prior! [5]
Let me make this explicit, as it’s not immediately clear. In DINO, we also have a student and teacher model. To distinguish their input signals, the student receives local crops of $96\times 96$ while the teacher receives global crops of $224\times 224$ (in practice, the student also receives global crops, but we’re keeping things simple!) This is the heart of DINO’s local-to-global correspondence prior, and is similar to the I-JEPA prior above: we want the student representation to be informative enough that it can match the teacher’s global view (with the same tricks used to prevent collapse).
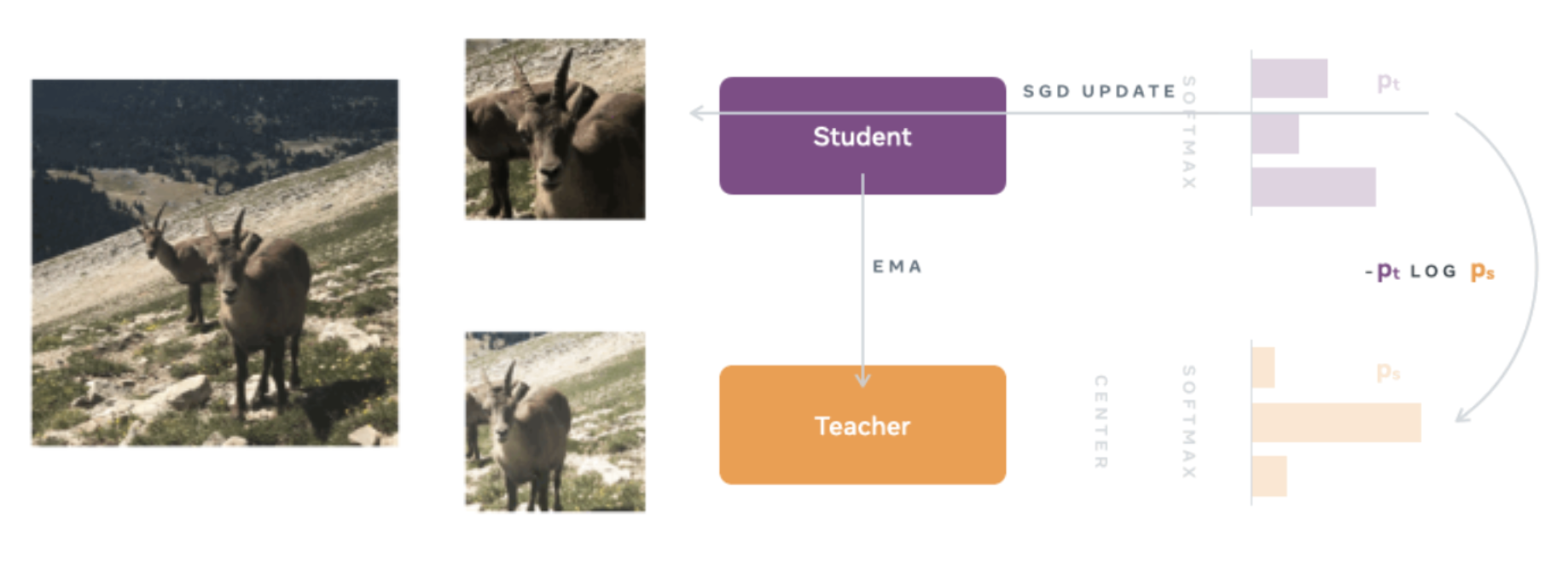
Overview of the DINO architecture.
The only difference, obviously, is in how we supervise the representations. Here, we adopt a knowledge distillation framework (hence the name, distillation with no labels, or DINO) and match the distributions by a cross-entropy loss, i.e.
$$ \min_{\theta_s} -p_t \log p_s. $$
Simplicity is key—all that’s needed to prevent representation collapse is an EMA with a centering and sharpening of the teacher outputs.
Allow me to indulge in a brief tangent enlightened on me by the DINO paper. Interestingly, DINO is like the ultimate evolution of BYOL (Bootstrap Your Own Latent). BYOL was one of the first SSL works that obtained good results without contrasting between images, instead matching features from a student to a teacher trained with momentum using MSE. However, having a predictor was crucial so that the representations did not collapse (as well as the batch norm…). DINO adopted virtually the same architecture, but used cross entropy (i.e., distillation), and found that now the predictor (marginally) hurt performance (see Table 7 [5])! So much for JEPA motivation; empiricism wins out in the end. The entire Appendix B of the DINO paper is a great read, honestly.
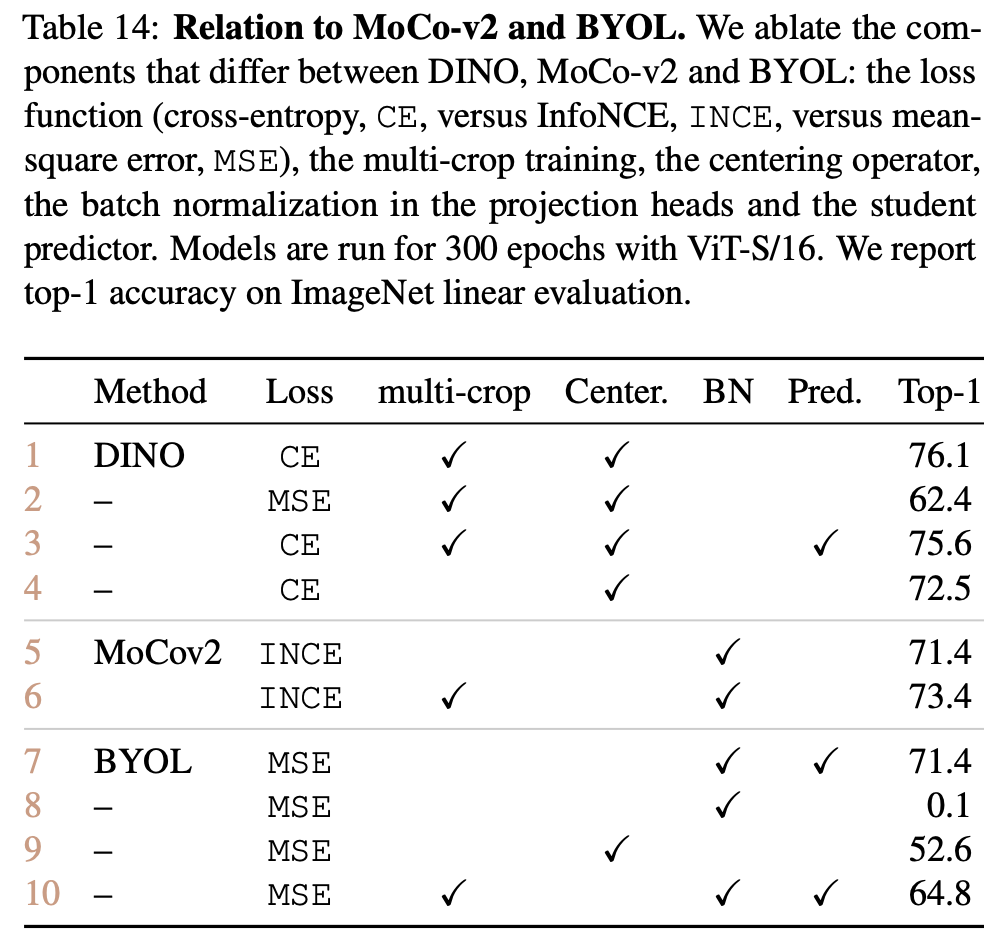
Table 14 from Appendix B, with detailed ablations of DINO compared to MoCo and BYOL.
In fact, I-JEPA also uses MSE on its representations, and requires a predictor (again, in a slightly different manner). They do an ablation where they use MSE on pixel-loss and it does much worse, but I’m not sure I trust how hard they tried for that experiment.
Back to JEPA business. Now you might say, gee Tyler, I actually think this also sounds a lot like MAE, to which I’d say, you’re also correct. The paper itself mentions:
Our encoder/predictor architecture is reminiscent of the generative masked autoencoders (MAE) [36] method. However, one key difference is that the I-JEPA method is non-generative and the predictions are made in representation space.
It’s more similar in that there is an explicit predictor conditioned on some latent variable $z$, so the predictor is “controllable” or “targeted”. But I find the specific architecture is more similar, since generative methods don’t have the same pressure to prevent collapse. In other words, to be honest, all these methods have similar priors, which actually are grounded in our data. We’re just doing context-prediction, which is like a bi-directional next token prediction, although just not as dense.
V-JEPA is unsurprisingly MAE
Now that I’ve primed you, this next part shouldn’t be surprising. Although I will say that this point was lost on me the first (and second, and third, and …) time I tried understanding V-JEPA. [10]
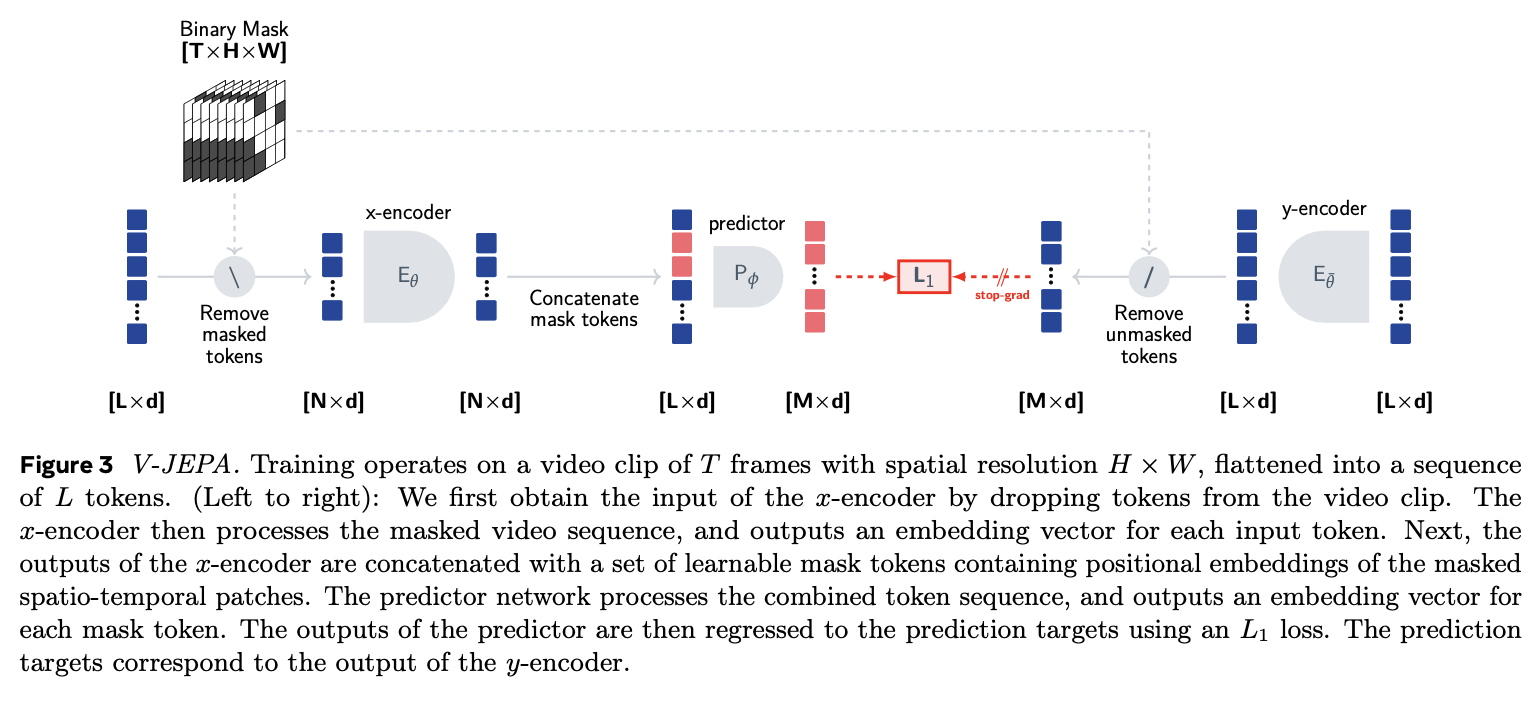
Overview of the V-JEPA architecture.
For extending to videos, V-JEPA full on adopts the MAE pipeline. This means that they generate masks starting with a few contiguous spatial segments expanded through time (which forms the target), and removing those to get the context. The remaining tokens are fed through the encoder, and then the mask tokens $z$ are added back for a predictor/decoder to predict what the masked tokens should be. These are supervised using $L_1$ against the target representations, i.e., the $y$-encoder, which is just an EMA of the $x$-encoder.
The diagram is not terribly clear. In particular, the non-mask tokens are dropped from the predictor, even though it clearly predicts everything (just like MAE). The only difference is that we’re supervising in latent space, not pixel space. This makes sense—there are too many high frequency details for learning great representations, so even MAE does some post processing like normalizing the images as a target instead. Also inputs are provided both on the left and the right, which should be a cardinal sin of diagram creation.
Here’s a picture of the MAE architecture to remind you.
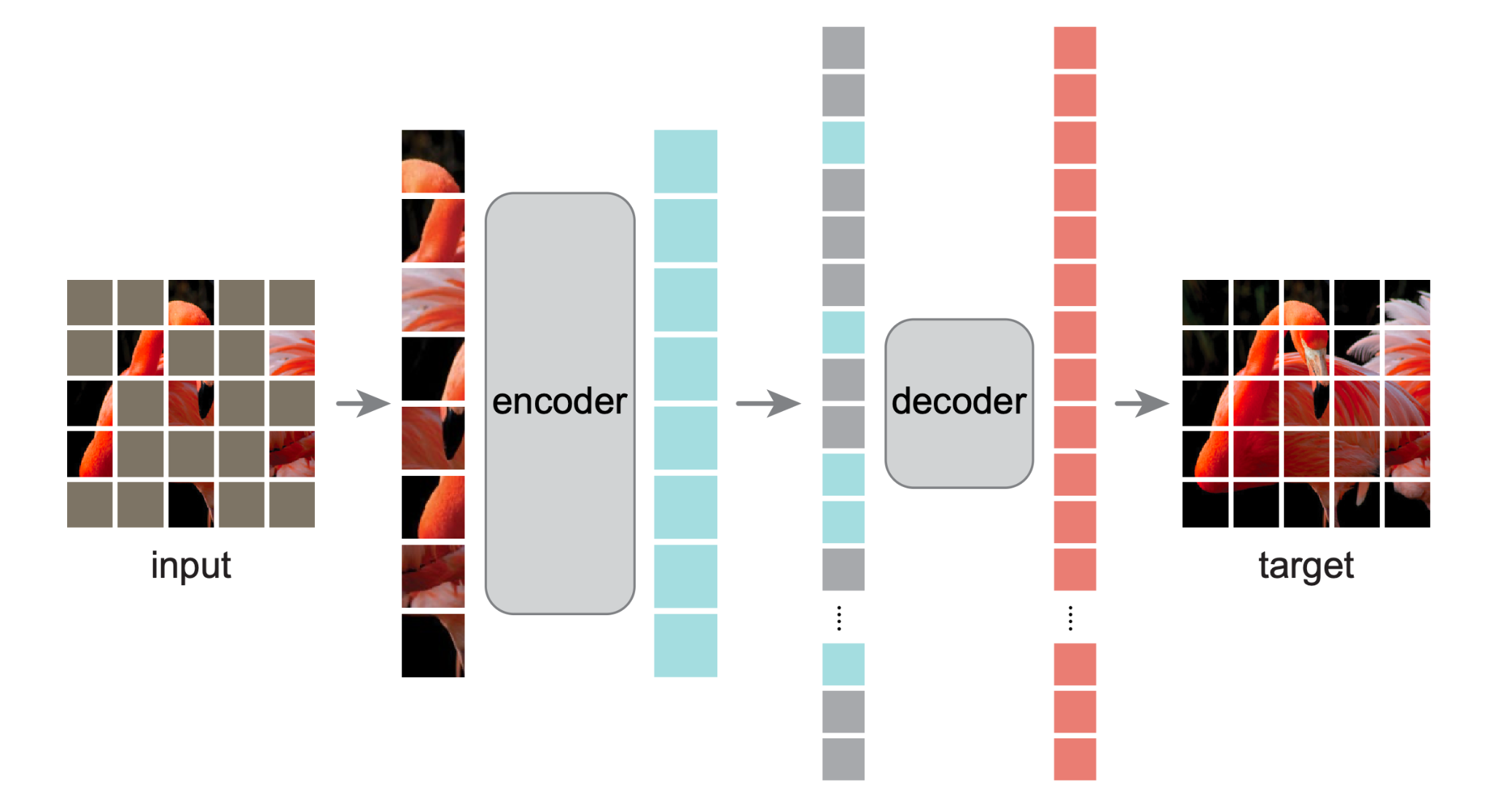
Overview of the MAE architecture.
In this sense, I actually don’t disagree with V-JEPA at all then. It does away with many of the high frequency details which plague MAE, but in turn then needs to deal with supervising latent representations. This requires borrowing from the standard SSL literature, for pretty good results.
Parting Thoughts
I have two main thoughts. The first is that when I first interpreted Yann’s “no-pixel-supervision” claim, I thought he meant we need to do away with using priors about pixel data, i.e., images. It turns out that he really just means no pixel supervision, literally. Amidst all the marketing that point got lost, but seeing as he’s just getting around MAE weakest spot of high frequency pixel noise (even keeping the dense prediction you get compared to I-JEPA), I like it a lot. We’re not throwing away structure that we can take advantage of, but actually leveraging it in our prior.
The only weird thing is that the latents for some reason aren’t as immediately usable as say DINO. Anecdotally in a few of my projects, I’ve tried using frozen V-JEPA 2 representations for VLMs and just for representation analysis (primarily in multimodal settings), and they’ve been much worse than other frozen representations. From chatting with others I’m not the only one with this problem, but maybe they’re just not semantic at all.
The second is that I’m not convinced that this specific framework has to be it. I’m sure that goes without saying, but JEPA was not the pioneer in any sense of neither SSL nor latent prediction. It built on a whole host of works that carved the landscape out, and it will continue to be one of many works which approach SSL with its own angle. Only time will tell which approach survives. DINO is already on version 3 and well and alive, as well as Perception Encoder (which is a Hiera model, a descendant of MAE actually!) and SigLIP as alternative approaches.
There’s also data flywheel approaches like SAM which one could consider as active or curriculum learning, but have been immensely popular while still being “semi-supervised” in a sense. Recurrent models like Recurrent Masked Auto-Encoders are also refreshing takes on a field that has felt mostly stagnant for new ideas, revisiting our assumptions on an input signal level.
All of this is to say: representation learning is far from dead—it is alive more than ever!
References
[1] Maes, L., Le Lidec, Q., Scieur, D., et al. "LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels." arXiv preprint arXiv:2603.19312 2026.
[2] Chen, T., Kornblith, S., Norouzi, M., et al. "A Simple Framework for Contrastive Learning of Visual Representations." ICML 2020.
[3] He, K., Fan, H., Wu, Y., et al. "Momentum Contrast for Unsupervised Visual Representation Learning." CVPR 2020.
[4] Grill, J., Strub, F., Altché, F., et al. "Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning." NeurIPS 2020.
[5] Caron, M., Touvron, H., Misra, I., et al. "Emerging Properties in Self-Supervised Vision Transformers." ICCV 2021.
[6] Radford, A., Kim, J. W., Hallacy, C., et al. "Learning Transferable Visual Models From Natural Language Supervision." ICML 2021.
[7] Zhai, X., Mustafa, B., Kolesnikov, A., et al. "Sigmoid Loss for Language Image Pre-Training." ICCV 2023.
[8] He, K., Chen, X., Xie, S., et al. "Masked Autoencoders Are Scalable Vision Learners." CVPR 2022.
[9] Assran, M., Duval, Q., Misra, I., et al. "Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture." CVPR 2023.
[10] Bardes, A., Garrido, Q., Ponce, J., et al. "Revisiting Feature Prediction for Learning Visual Representations from Video." arXiv preprint arXiv:2404.08471 2024.